
OpenSearch
L’ultima volta che ho parlato di OpenSearch era nel post di Graylog.
OpenSearch è una suite open-source (licenza Apache 2.0) e community driven altamente scalabile e flessibile.
L’ennesimo progetto legato ad Apache Lucene?
OpenSearch nasce per colmare il vuoto creato da Elasticseach, quando l’azienda che lo manutiene ha deciso di modificare la licenza d’uso. Ora non staremo ad approfondire questa cosa, ma se sei interessato ti metto delle risorse in fondo al post.
Va quindi catalogato come software orientato all’indicizzazione, ricerca e osservabilità. Da elastic eredita flessibilità, scalabilità e semplicità di gestione.
Ok bello, ma cosa permette di fare?
Uno delle funzionalità spacca mercato di OpenSearch è di certo la ricerca “full text” che permette di ricercare all’interno di tutti i campi indicizzati dando un peso diverso in base ai risultati emersi (sto semplificando per ovvi motivi).
E’ anche possibile analizzare grandi quantità di dati, in gergo chiamati big data, e configurando il sistema di allarmi si può usare come cane da guardia.
Per chiudere un po’ il cerchio, aggiungo che OpenSearch è molto orientato alla alta affidabilità e alla scalabilità orizzontale. Questa vocazione permette di creare in maniera veloce dei cluster senza rinunciare alla sicurezza. A corredo sono rilasciati anche una serie di “tool” che estendono le funzionalità e le possibili integrazioni (Dashboards, Ingest Tools, CLI, etc).
Mani in pasta
Nella sezione download del sito è possibile scaricare sia OpenSearch che i tools che abbiamo citato prima.
Per rendere il tutto ancora più agnostico rispetto al sistema operativo partirò dall’archivio tar.
Prerequisiti
La prima cosa da avere è Java e nell’archivio tar troveremo la versione OpenJDK 17. Scarichiamo, spacchettiamo e creiamo un link per lavorare in maniera più comoda
# cd /opt
# wget https://artifacts.opensearch.org/releases/bundle/opensearch/2.6.0/opensearch-2.6.0-linux-x64.tar.gz
# tar xfz opensearch-2.6.0-linux-x64.tar.gz
# ln -s opensearch-2.6.0 opensearch
NB: Assicuriamoci di avere almeno 2 GB di SWAP.
Nel caso foste carenti e voleste velocizzare la cosa
# fallocate -l 2G /swapfile
# chmod 600 /swapfile
# mkswap /swapfile
# swapon /swapfile
Prima configurazione
All’interno della cartella opensearch troveremo
# ll
total 272
drwxr-xr-x. 3 vagrant vagrant 4096 Feb 24 19:22 bin
drwxr-xr-x. 9 vagrant vagrant 4096 Feb 24 19:22 config
drwxr-xr-x. 9 vagrant vagrant 121 Feb 23 19:20 jdk
drwxr-xr-x. 3 vagrant vagrant 4096 Feb 23 19:20 lib
-rw-r--r--. 1 vagrant vagrant 11358 Feb 23 19:20 LICENSE.txt
drwxr-xr-x. 2 vagrant vagrant 6 Feb 23 19:20 logs
-rw-r--r--. 1 vagrant vagrant 7486 Feb 24 19:22 manifest.yml
drwxr-xr-x. 20 vagrant vagrant 4096 Feb 23 19:20 modules
-rw-r--r--. 1 vagrant vagrant 228525 Feb 23 19:20 NOTICE.txt
-rwxr-xr-x. 1 vagrant vagrant 2339 Feb 24 19:21 opensearch-tar-install.sh
drwxr-xr-x. 5 vagrant vagrant 42 Feb 24 19:22 performance-analyzer-rca
drwxr-xr-x. 20 vagrant vagrant 4096 Feb 24 19:22 plugins
-rw-r--r--. 1 vagrant vagrant 3664 Feb 23 19:20 README.md
Nella cartella conf, tra le altre cose, troveremo jvm.options e opensearch.yml.
Nel file jvm.options impostiamo la memoria minima e massima: in una istanza dedicata a OpenSearch è consigliabile impostare il 50% della RAM a disposizione.
...
-Xms1g
-Xmx1g
...
Facciamo un backup del file opensearch.yml e inseriamo solo le properties che ci interessano
opensearch.yml
cluster.name: openStorm
path.data: /var/lib/opensearch
path.logs: /var/log/opensearch
action.auto_create_index: false
plugins.security.disabled: true
network.host: 0.0.0.0
discovery.type: single-node
NB: ho semplificato all’osso le configurazioni per arrivare al punto. Magari, se la cosa genera interesse, farò un post dedicato.
Primo avvio
Creiamo un utente non privilegiato e proviamo ad avviare OpenSearch.
# adduser opensearch
# mkdir -p /var/lib/opensearch /var/log/opensearch
# chown -R opensearch. /opt/opensearch-2.6.0 /var/lib/opensearch /var/log/opensearch
creiamo il servizio systemd
/etc/systemd/system/opensearch.service
[Unit]
Description=opensearch
Wants=network-online.target
After=network-online.target
[Service]
RuntimeDirectory=opensearch
PrivateTmp=true
WorkingDirectory=/opt/opensearch
User=opensearch
Group=opensearch
ExecStart=/opt/opensearch/bin/opensearch -p /opt/opensearch/opensearch.pid -q
StandardOutput=journal
StandardError=inherit
# Specifies the maximum file descriptor number that can be opened by this process
LimitNOFILE=65536
# Specifies the memory lock settings
LimitMEMLOCK=infinity
# Specifies the maximum number of processes
LimitNPROC=4096
# Specifies the maximum size of virtual memory
LimitAS=infinity
# Specifies the maximum file size
LimitFSIZE=infinity
# Disable timeout logic and wait until process is stopped
TimeoutStopSec=0
# SIGTERM signal is used to stop the Java process
KillSignal=SIGTERM
# Send the signal only to the JVM rather than its control group
KillMode=process
# Java process is never killed
SendSIGKILL=no
# When a JVM receives a SIGTERM signal it exits with code 143
SuccessExitStatus=143
[Install]
WantedBy=multi-user.target
avviamo il nostro nuovo amico di ricerca
# systemctl daemon-reload
# systemctl enable --now opensearch
# systemctl status opensearch
Test
Per avere una prova che il nostro OpenSearch stia funzionando basta una semplice curl
# curl localhost:9200
{
"name" : "AlmaLinux",
"cluster_name" : "openStorm",
"cluster_uuid" : "3vSmTKttRvu8elPxiIxBNg",
"version" : {
"distribution" : "opensearch",
"number" : "2.6.0",
"build_type" : "tar",
"build_hash" : "7203a5af21a8a009aece1474446b437a3c674db6",
"build_date" : "2023-02-24T18:57:04.388618985Z",
"build_snapshot" : false,
"lucene_version" : "9.5.0",
"minimum_wire_compatibility_version" : "7.10.0",
"minimum_index_compatibility_version" : "7.0.0"
},
"tagline" : "The OpenSearch Project: https://opensearch.org/"
}
Extra
Per interagire in maniera più comoda con OpenSearch esiste un software che si chiama cerebro.
Anche cerebro è scritto in java ed è una web application in ascolto sulla porta 9000.
 Una volta inserito come target http://[IP_SERVER]:9200/
Una volta inserito come target http://[IP_SERVER]:9200/
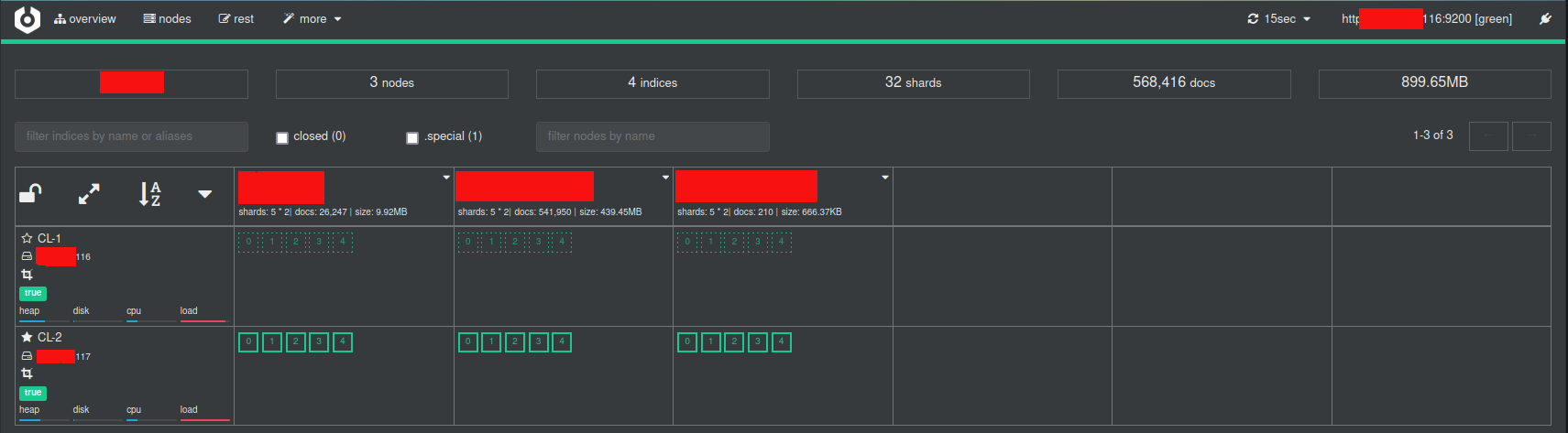
Senza dilungarci troppo con cerebro è possibile gestire il cluster, gli indici e lanciare le query con il rest client integrato.
Le opinioni in quanto tali sono opinabili e nulla ti vieta di approfondire l’argomento.
Risorse: