
Graylog
 Negli ultimi anni si è sempre più sentito parlare di loging centralizzato e questo vociferare si è trasformato sempre più in un’esigenza concreta.
I più grandi player hanno messo sul piatto le loro proposte (vedi Splunk, Datadog, LogDNA, ….) e per fortuna anche il mondo open non si è fatto attendere.
Negli ultimi anni si è sempre più sentito parlare di loging centralizzato e questo vociferare si è trasformato sempre più in un’esigenza concreta.
I più grandi player hanno messo sul piatto le loro proposte (vedi Splunk, Datadog, LogDNA, ….) e per fortuna anche il mondo open non si è fatto attendere.
Ho installato per la prova volta Graylog Open nel 2012 e mi sono reso subito conto delle sue potenzialità; mette a disposizione diversi ingest per macinare log su log, indicizzarli e permettere quindi delle ricerche mirate avendoli a disposizione per il tempo che più ci aggrada.
Ci sono varie modalità di fruizione che vanno dal container docker, al cloud, alla macchina on-premise ma oggi vi mostrerò passo dopo passo l’installazione su una macchina virtuale basata su Red Hat 8 (RHEL compatibile).
NB: per le varie componenti del backend infrastrutturale (MongoDB e Elasticsearch) verrà mostrata l’installazione single-node ma entrambi gli engine offrono la possibilità di avere alta affidabilità e scalabilità orizzontale.
Installazione
Prerequisiti
MongoDB
Per quanto riguarda il database useremo una distribuzione MongoDB compatibile. Ho gia parlato di Percona Server for MongoDB e quindi non entrerò troppo nel dettaglio.
Aggiungiamo i repository, attiviamo, installiamo e avviamo la versione che ci interessa (MongoDB 5.x),
# dnf install https://repo.percona.com/yum/percona-release-latest.noarch.rpm
# percona-release enable psmdb-50 release
# dnf install percona-server-mongodb
# systemctl enable --now mongod
Non ci sono particolari accorgimenti se non le solite raccomandazioni sulla sicurezza e il controllo degli accessi che sono già state trattate.
Elasticsearch
In questo caso opteremo per un progetto 100% open come Opensearch. Non ho ancora parlato di questo progetto nello specifico ma uscirà presto almeno un post a lui dedicato. Per ora ci limiteremo ad installare e avviare un’istanza singola.
Aggiungiamo i repository e carichiamo di metadati
# curl -SL https://artifacts.opensearch.org/releases/bundle/opensearch/2.x/opensearch-2.x.repo -o /etc/yum.repos.d/opensearch-2.x.repo
# rpm --import https://artifacts.opensearch.org/publickeys/opensearch.pgp
# dnf clean all && dnf repolist
Per installare l’ultima versione della 2 e la openjdk
# dnf install opensearch java-17-openjdk
A questo punto editiamo il file /etc/opensearch/opensearch.yml e prestiamo attenzione a questi parametri:
cluster.name: graylog
path.data: /var/lib/opensearch
path.logs: /var/log/opensearch
action.auto_create_index: false
plugins.security.disabled: true
network.host: 127.0.0.1
discovery.type: single-node
NB: se queste variabili esistono modifichiamole e se mancano aggiungiamole.
Se siamo stati bravi l’avvio andrà liscio come l’olio
# systemctl enable --now opensearch
verifichiamo lo stato con
# systemctl status opensearch
Graylog
Attiviamo i repository e installiamo graylog
# rpm -Uvh https://packages.graylog2.org/repo/packages/graylog-5.0-repository_latest.rpm
# dnf install graylog-server
Editiamo il file /etc/graylog/server/server.conf e impostiamo la chiave di cifratura e la password di accesso (password_secret e root_password_sha2). Non dimentichiamoci il bind:
....
http_bind_address = 0.0.0.0:9000
....
Per calcolare sia lo sha2 della root password che della secret c’è un comando molto comodo
echo -n "Enter Password: " && head -1 </dev/stdin | tr -d '\n' | sha256sum | cut -d" " -f1
Se abbiamo fatto tutto per bene
# systemctl daemon-reload
# systemctl enable --now graylog-server.service
Per concludere colleghiamoci all’interfaccia http://[IP-SERVER-LOG]:9000 e inseriamo le credenziali. Se non abbiamo specificato altro nel file di configurazione l’utente di default è admin.
Configurazione
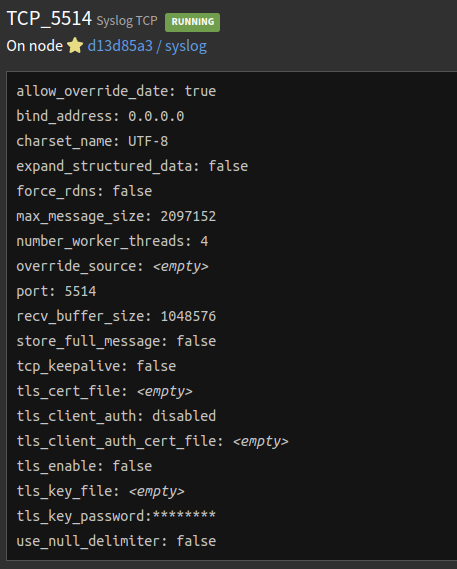
Come prima cosa andiamo nella sezione inputs e avviamo il syslog su protocollo TCP
A questo punto non ci resta che iniziare ad inviare i nostri log al server Graylog.
Esempio
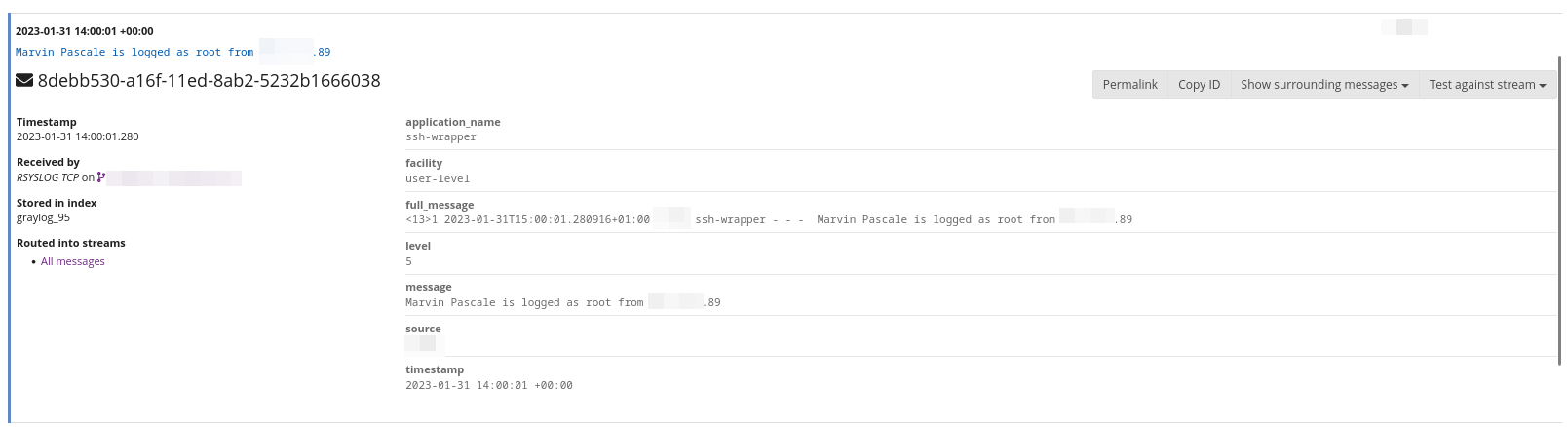
Ecco un esempio di una login ssh come utente root registrata su Graylog. Con le giuste configurazioni è possibile ottenere delle registrazioni parlanti.
Chiarimenti
Per non rendere il post troppo lungo e dispersivo, non sono stati trattati i temi della sicurezza per ogni singola componente che restano sempre estremamente importanti. Vi consiglio quindi di approfondire questi temi non solo per Graylog ma anche per Percona server for MongoDB e Opensearch.
Come detto in precedenza, tutte queste componenti offrono la possibilità di avere un cluster in HA per cui se hai esigenze particolari non temere; sarà possibile scalare orizzontalmente l’infrastruttura per assorbire grandi carichi di lavoro e offrire una resilienza ai dati.
Le opinioni in quanto tali sono opinabili e nulla ti vieta di approfondire l’argomento.
Risorse: