
Minio Baremetal
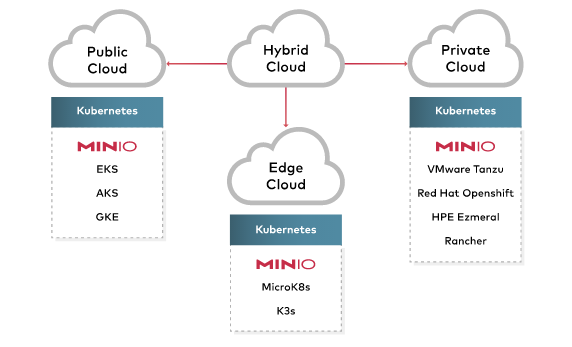
Conosco da tempo questo bel progetto open-source ma di recente ho avuto il piacere di lavorarci in maniera intensiva. Sono partito da una situazione di test (1 nodo) per arrivare ad una soluzione pensata per la messa in produzione (4 nodi con disco dati dedicato).
Minio Baremetal
MinIO è un object storage ad altre prestazione rilasciato sotto licenza Apache License v2.0. Come detto in precedenza è compatibile con le API Amazon S3 e questo lo rende appetibile in tutte quelle situazioni in cui è possibile/necessario utilizzare questo tipo di storage.
MinIO Object Storage utilizza i bucket per organizzare gli oggetti. Un bucket è simile a una cartella in un filesystem. Ogni bucket può contenere un numero arbitrario di oggetti. I bucket di MinIO forniscono la stessa funzionalità dei bucket AWS S3.
MinIO utilizza “Erasure Coding”. Erasure Coding fornisce alta disponibilità, affidabilità e ridondanza dei dati archiviati su un cluster di MinIO. MinIO divide gli oggetti in blocchi e li distribuisce uniformemente su ciascuna unità che fanno parte del cluster.
Il cluster semplice in MinIO viene chiamato server-pool e viene definito in fase di avvio. E’ possibile utilizzabili le iterazioni tipiche di bash e quindi per avviare un server-pool composto da 4 nodi con 1 disco per nodo basterà avviare il servizio così:
# minio server https://minio{1...4}.local.domain/mnt/minio-disk
Avviando tutti e quattro i nodi con con gli stessi argomenti verrà inizializzato il server-pool.
Viene definito cluster un infrastruttura composta da più server-pool.
# minio server https://minio{1...4}.local.domain/mnt/minio-disk https://minio{5...9}.local.domain/mnt/minio-disk
In questo caso verranno avviati due server-pool ciascuno costituito da 4 nodi con 1 disco per nodo. MinIO archiverà ogni oggetto con le sue eventuali versioni sullo stesso server-pool. Questa funzionalità dona una scalabilità orizzontale ma non permette di migrare i dati tra un set e l’altro.
Caratteristiche interessanti
Bucket Notifications
Questa funzionalità consente di pubblicare automaticamente le notifiche su una o più endpoint configurati per attivarsi quando si verificano eventi specifici in un bucket (creazione, modifica, cancellazione, ecc).
Bucket Versioning
Il controllo delle versioni del bucket MinIO supporta la conservazione di più “versioni” di un oggetto in un singolo bucket. Le operazioni di scrittura che normalmente sovrascriverebbero un oggetto esistente creano invece un nuovo oggetto gestito tramite un numero di versione.
Erasure Coding
MinIO Erasure Coding è una funzione di ridondanza e disponibilità dei dati che consente a MinIO di ricostruire automaticamente gli oggetti in caso di perdita di una o più unità o nodi del cluster. L’Erasure Coding fornisce una riparazione a livello di oggetto con un carico inferiore rispetto alle tecnologie come replica o RAID.
Mani in pasta
Per iniziare a giocare con MinIO abbiamo diverse alternative:
- download e avvio dell’eseguibile;
- avviare un docker container;
- deploy su Kubernetes;
- …
Avvio su Linux
Avviare MinIO è molto semplice; bisogna scaricare e avviare il binario.
# curl https://dl.min.io/server/minio/release/linux-amd64/minio \
--create-dirs \
-o $HOME/bin/minio
# chmod +x $HOME/bin/minio
# export MINIO_ACCESS_KEY=marv.ino && export MINIO_SECRET_KEY=marv.ino && minio server /mnt/minio-disk
Avvio con docker
Se volete solo testarlo vi consiglio di utilizzare docker che resta sempre la soluzione più pulita e semplice.
# docker run -d -p 9000:9000 \
--name minio \
-v /opt/minio/data:/data \
-e "MINIO_ROOT_USER=marv.ino" \
-e "MINIO_ROOT_PASSWORD=marv.ino" \
minio/minio server /data
E’ anche possibile non salvare nessun dato rimuovendo il parametro -v /opt/minio/data:/data
# docker run -d -p 9000:9000 \
--name minio \
-e "MINIO_ROOT_USER=marv.ino" \
-e "MINIO_ROOT_PASSWORD=marv.ino" \
minio/minio server /data
In entrambi i casi dopo l’avvio basterà aprire un browser su http://localhost:9000/ e sarà possibile eseguire il login. La prima cosa da fare è la creazione di un nuovo bucket.
Test e cli
Un test veloce può essere fatto utilizzando le awscli. Basterà configurare il nuovo profilo con il giusto endpoint.
[profile minio]
region = main
output = json
s3 =
endpoint_url = http://localhost:9000
s3api =
endpoint_url = http://localhost:9000
e le credenziali
[minio]
aws_access_key_id = marv.ino
aws_secret_access_key = marv.ino
ora non ci resta che testare
# aws --profile minio s3 ls
Tutte queste operazioni posso anche essere eseguite dal client dedicato (mc).
Extra
Per ottenere il meglio dal nostro cluster sarà necessario ottimizzare il sistema operativo. A tal proposito sono partito dal un repo Github di MinIO
#!/bin/bash
cat > sysctl.conf <<EOF
# maximum number of open files/file descriptors
fs.file-max = 4194303
# use as little swap space as possible
vm.swappiness = 1
# prioritize application RAM against disk/swap cache
vm.vfs_cache_pressure = 50
# minimum free memory
vm.min_free_kbytes = 1000000
# follow mellanox best practices https://community.mellanox.com/s/article/linux-sysctl-tuning
# the following changes are recommended for improving IPv4 traffic performance by Mellanox
# disable the TCP timestamps option for better CPU utilization
net.ipv4.tcp_timestamps = 0
# enable the TCP selective acks option for better throughput
net.ipv4.tcp_sack = 1
# increase the maximum length of processor input queues
net.core.netdev_max_backlog = 250000
# increase the TCP maximum and default buffer sizes using setsockopt()
net.core.rmem_max = 4194304
net.core.wmem_max = 4194304
net.core.rmem_default = 4194304
net.core.wmem_default = 4194304
net.core.optmem_max = 4194304
# increase memory thresholds to prevent packet dropping:
net.ipv4.tcp_rmem = "4096 87380 4194304"
net.ipv4.tcp_wmem = "4096 65536 4194304"
# enable low latency mode for TCP:
net.ipv4.tcp_low_latency = 1
# the following variable is used to tell the kernel how much of the socket buffer
# space should be used for TCP window size, and how much to save for an application
# buffer. A value of 1 means the socket buffer will be divided evenly between.
# TCP windows size and application.
net.ipv4.tcp_adv_win_scale = 1
# maximum number of incoming connections
net.core.somaxconn = 65535
# maximum number of packets queued
net.core.netdev_max_backlog = 10000
# queue length of completely established sockets waiting for accept
net.ipv4.tcp_max_syn_backlog = 4096
# time to wait (seconds) for FIN packet
net.ipv4.tcp_fin_timeout = 15
# disable icmp send redirects
net.ipv4.conf.all.send_redirects = 0
# disable icmp accept redirect
net.ipv4.conf.all.accept_redirects = 0
# drop packets with LSR or SSR
net.ipv4.conf.all.accept_source_route = 0
# MTU discovery, only enable when ICMP blackhole detected
net.ipv4.tcp_mtu_probing = 1
EOF
echo "Enabling system level tuning params"
sysctl --quiet --load sysctl.conf && rm -f sysctl.conf
# `Transparent Hugepage Support`*: This is a Linux kernel feature intended to improve
# performance by making more efficient use of processor’s memory-mapping hardware.
# But this may cause https://blogs.oracle.com/linux/performance-issues-with-transparent-huge-pages-thp
# for non-optimized applications. As most Linux distributions set it to `enabled=always` by default,
# we recommend changing this to `enabled=madvise`. This will allow applications optimized
# for transparent hugepages to obtain the performance benefits, while preventing the
# associated problems otherwise. Also, set `transparent_hugepage=madvise` on your kernel
# command line (e.g. in /etc/default/grub) to persistently set this value.
echo "Enabling THP madvise"
echo madvise | sudo tee /sys/kernel/mm/transparent_hugepage/enabled
Ho utilizzato questo script per realizzare parte del mio playbook ansible. A tal proposito consiglio di dare un occhio a questo repo: ansible-minio .
Le opinioni in quanto tali sono opinabili e nulla ti vieta di approfondire l’argomento.
Risorse: